Fast New ELO Over MixEval. But Looking into Code, I Got Doubts!
Have you seen that MixEval Hard has two interesting but little critical aspects
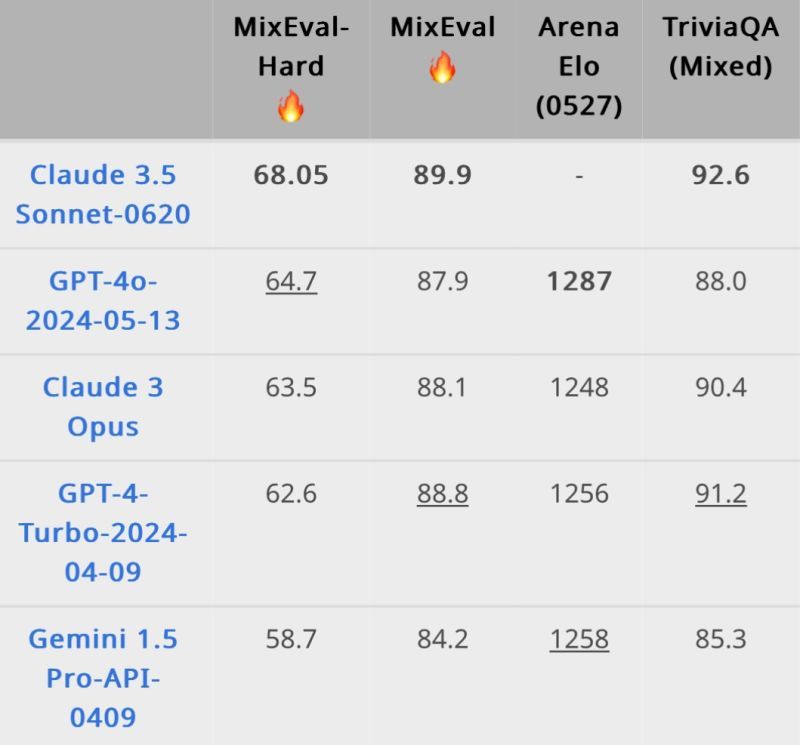
TLDR
- Examined MixEval, an open-source LLM benchmark
- Uses LLMs as judges to predict continuous values
- Evaluation data contains duplicates
- Uncertain about trusting these methods
Issues with MixEval
- For freeform answering, it lets e.g. GPT35T as judge predict values like "[[0.9]]" and try to fetch this as reliable number for correctness score.
- The MixEval eval data contains several duplicates due to their sampling approach.
My Take
I like the concept of MixEval to have an open-source LLM benchmark which has a good overlap to Arena Elo, but I am unsure if I trust LLMs as judge which try to reason continuous numbers for freeform LLM answers and relies on duplicates in samples.
Extract of My Hands-On Criteria
- What do you think?
- Do you see an issue in duplicates within eval sets?
- Would you trust LLMs as judge predicting continuous values for later usage?
Credit
Thanks Philipp Schmid for your post(s)
My Questions?
- What are your thoughts on MixEval?
- Do you trust LLMs as judges in evaluating continuous values?
- How do you handle duplicates in evaluation sets?
#generativeai #artificialintelligence #llm #machinelearning #benchmark
- ← Previous
Do we need another GenAI solution? How & why we developed a full-stack GenAI LLM+RAG tool called Alan. A sneak peek at what I am currently working on. - Next →
Alternative to GenAI creativity? Watch and try out these fun Evolutionary Algorithms. Problem-solving without GenAI and SGD-based approaches explained!