NVIDIA Benchmark might be WRONG cause it states - You lose money AND LLM inference speed if you add more NVIDIA A100. This NVIDIA Benchmark is NOT reliable.
Analyzing the reliability of NVIDIA's benchmark results and the implications for LLM inference speed and hardware investment.
TL;DR ⏱️
- Terms and background on LLMs and inference
- Strange findings in NVIDIA's benchmark results
- Concerns about the reliability of these benchmarks
- Questions and further reading on the topic
Terms 🏫
- LLMs are Large Language Models
- LLMs are a branch of Generative AI
- Those LLMs can be used to generate texts
- Text generation by LLMs is called Inference
- LLM Inference is faster on GPUs compared to CPUs
- Pretty common “LLM-GPU” is the NVIDIA A100
Background Story ⚙️
- We @Comma Soft AG are developing LLM pipelines
- Each use case has different requirements
- Sometimes Inference Speed is more important
- More Hardware performance can/should improve Inference speed
- To check out how much you can improve with more hardware, you can look into the scaling effect to see the trade-off between Inference speed and hardware costs
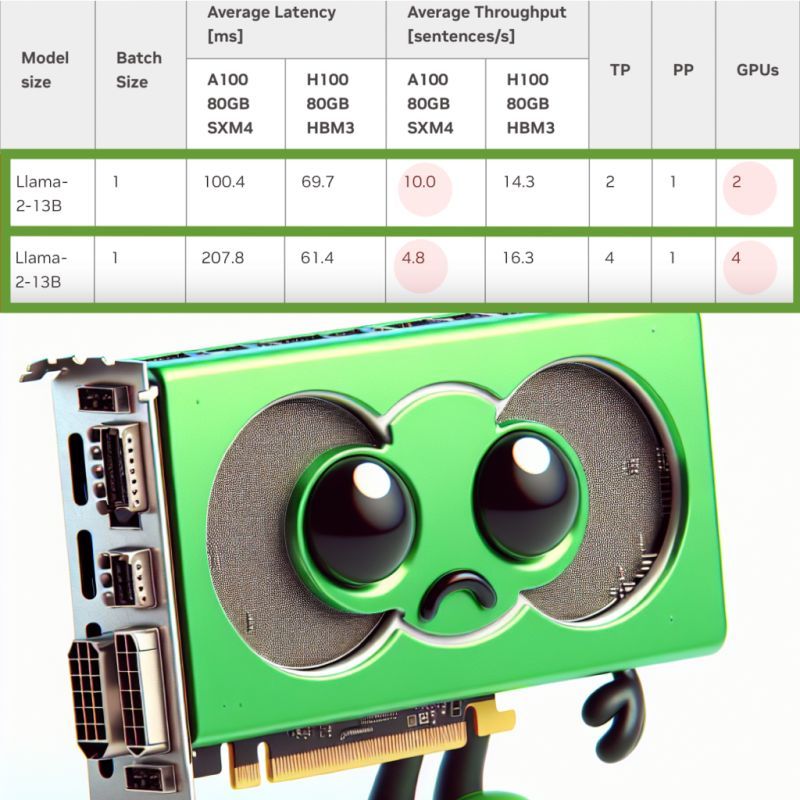
Weird Finding 🤔
- NVIDIA released a benchmark (link see below)
- It compares different GPU setups: 1, 2, 4, 8 GPUs for a common open-source model inference
- It states that when you increase from 2 GPUs to 4 GPUs you get half the throughput; from 10 sentences/sec to 4.8 sentences/sec for LLAMA-2 13B
My Take 🤗
- The NVIDIA Benchmark is broken or some hiccup with copy-paste of results
- Sentences/sec is a strange measure. Why not tokens per second which is more stable
- I found another strange issue with model sizes and performance on NVIDIA GPUs in this benchmark. see this link: https://rb.gy/5l8qqp
- It is a problem when you cannot trust benchmarks as this leads to reimplementing benchmarks or running them again which is a waste of resources and barely sustainable
- Benchmarks should be available open source to understand the measures and issues
Questions 🔠
- What do you think is the reason for this weird benchmark result?
- Do you have an idea why they measure in sentences per second and not in tokens per second?
- What are your preferred sources for benchmarks when it comes to Inference performance?
- What do you do to improve inference speed?
Links 📖
- NVIDIA AI Multi GPU Inference Benchmark: https://lnkd.in/e2sUsi63
- LLAMA 13B faster than LLAMA 7B? https://rb.gy/5l8qqp
- Mistrust in LLM Benchmarks! https://rb.gy/juw4pg
- Why do LLMs have sizes: 7B 13B, and 70B? https://rb.gy/zkpk5r
NVIDIA could you please fix it or comment on what was the issue/reason
For more content, brainstorming, and discussions, follow me or reach out to me 🥰
#LostInGenai #artificialintelligence #selectllm
- ← Previous
Too many LLMs?! How to keep track with all the Open Source Models? Identify the finetuned-masked LLMs and its position within the GenAI landscape! - Next →
What is your preferred LLM family? And do you start with an already finetuned LLM? Why you have chosen this LLM? I love to hear your perspective!