What is your preferred LLM family? And do you start with an already finetuned LLM? Why you have chosen this LLM? I love to hear your perspective!
Understanding the preferences and choices behind selecting specific LLM families and their finetuned variants.
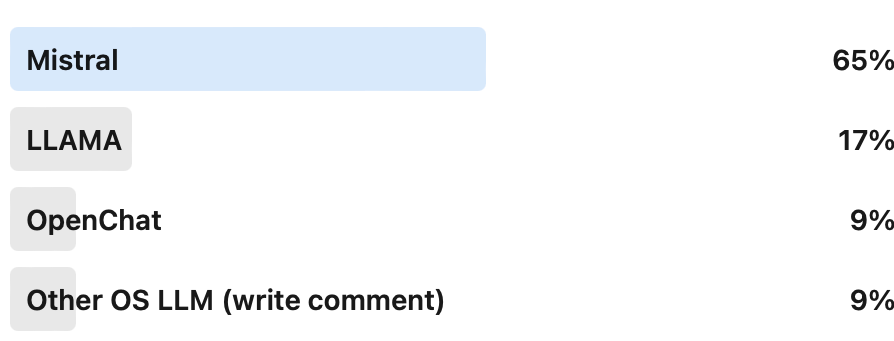
TL;DR ⏱️
- GenAI for text implemented by LLMs
- Many open-source models available
- Continuous influx of new models
- Key foundation model families
- LLM-based GenAI pipelines at Comma Soft AG
Background Information ⚙️
- GenAI for text can be implemented by LLMs
- LLMs are partially open-source available
- Day by day new models come to market or are published on platforms like Huggingface
- Many of them rely on certain Foundation model families
- Some of them exist in different sizes
- We @Comma Soft AG develop LLM based GenAI pipelines (sometimes using OS models like the ones in the survey)
Further Reading 📚
- Special infos about LLM licenses: https://lnkd.in/dtStQSdn
- Reason for LLM sizes: https://lnkd.in/dHRSJXgm
- Broken alignment in LLMs: https://lnkd.in/eWS-VZCD
- How to keep track of all these LLMs: https://lnkd.in/duGzWugD
- Problems tokenizer language capabilities: https://lnkd.in/edgPsdKz
- Issues with LLM benchmark results: https://lnkd.in/dmBeQZ_j
If you need support with LLM R&D or simply want to chat, reach out to me and follow me for more content ❤️
- ← Previous
NVIDIA Benchmark might be WRONG cause it states - You lose money AND LLM inference speed if you add more NVIDIA A100. This NVIDIA Benchmark is NOT reliable. - Next →
Who will take care of truly low-resource languages? A good step towards more fair GenAI LLM pricing at OpenAI for Japanese-using people!