Meta’s Llama 4 Release – Issues with Elo Scores?
LLaMA 4 is here – but questions remain about Elo Scores and benchmarks.
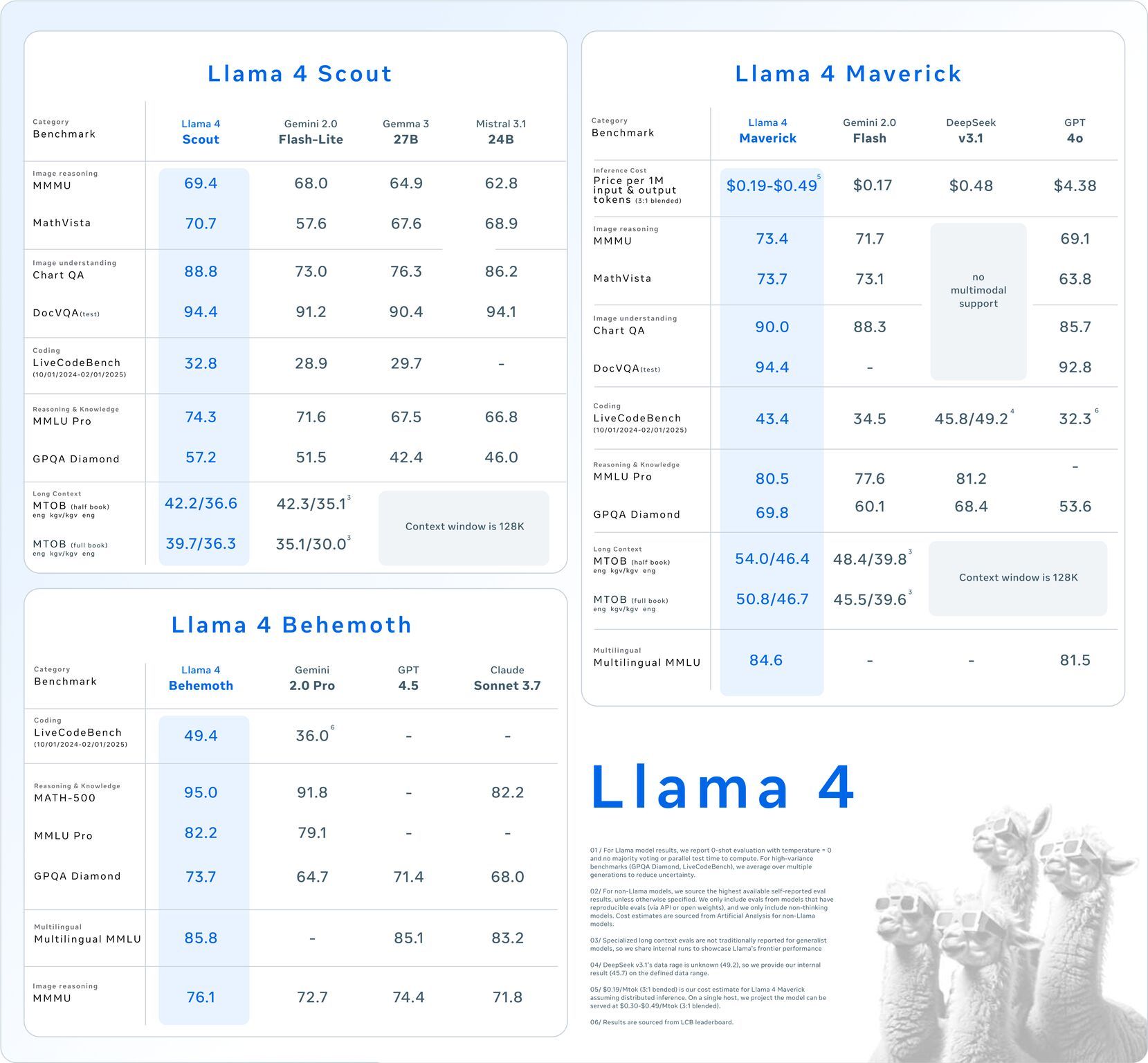
TL;DR ⏱️
- Wait for verified SOTA benchmark results and reliable Elo scores
- Elo Score #2 based on "Experimental" Maverick raises questions
- Meta switched to Mixture of Experts (MoE) architecture, similar to DeepSeek and Mistral
- Released multiple model sizes, scaling up to 2 trillion parameters
- Proposing multi-million token context windows
Background
Meta has officially released its LLaMA 4 models. While this is a major milestone, questions around transparency and evaluation metrics remain. Benchmark credibility and honest Elo scores are key to understanding the true capabilities of these models.
What have I done:
I took a closer look at the LLaMA 4 release details, especially their claims around Elo scores, context length, and the new Mixture of Experts approach. I also compared Meta’s direction with what we’ve recently seen from DeepSeek AI and Mistral AI.
IMHO:
🔍 Excited to see benchmarks on multi-million tokens and whether the "lost in the middle" effect persists.
🤔 Curious to see who will actually deploy the largest model in production.
🔄 The MoE trend improves throughput by reducing active parameters, but it still demands massive VRAM.
😤 Questionable whether the "Experimental" Maverick model matches the performance of the officially published models.
❤️ Feel free to reach out and like if you want to see more of such content.
#llama #artificialintelligence #llm