Meta’s LLaMA 4 Fraud Has Been Exposed!
AI Benchmarks and the Meta LLaMA 4 Controversy
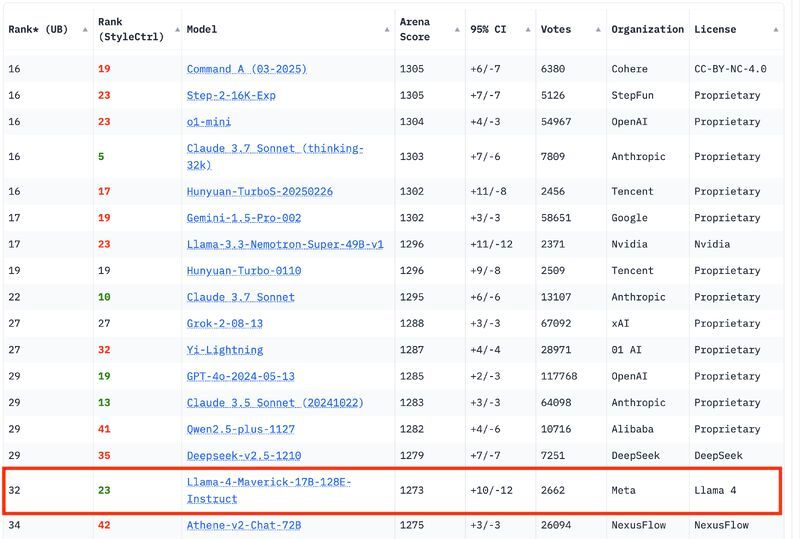
TL;DR ⏱️
- Meta’s Arena Elo #2 model is not the same as the Hugging Face version
- Performance discrepancies raise trust issues in AI benchmarks
- Benchmark gaming and contamination are growing concerns
Background
📢 Recent concerns arose when Meta’s LLaMA 4 model ranked #2 on Arena Elo.
🤔 It turned out the model available on Hugging Face wasn’t the same one as used in the benchmark.
This triggered questions around the reliability of AI benchmarks and the fairness of model comparisons.
What have I done:
🔍 Confirmed that the experimental Arena Elo model differs from the Hugging Face release.
📉 Tested the HF version and found that its performance didn’t match expectations.
🌍 Noted that its usability in the EU is already limited — now with lower impact.
⚠️ Collected examples of benchmark contamination and models fine-tuned specifically to game scores.
IMHO:
❤️🩹 I feel sorry for the Meta AI researchers who worked hard on this — it’s hard to imagine they supported any attempt at deception.
🔄 That’s why at Comma Soft AG, we continue to evaluate models continuously, beyond leaderboard hype.
📈 The key is to analyze how models perform in real-world agent pipelines (like Alan.de), not just on SOTA benchmarks.
❤️ Feel free to reach out and like if you want to see more of such content.
#AIBenchmarks #Meta #Huggingface #LLaMA4 #AIModels