Risk of LLMs Getting Stuck in Local Optima – Are We Training Optimally?
Local Optima Risk in Large Language Model Training
TL;DR ⏱️
- LLMs risk getting stuck in local optima during training
- Extreme dimensionality reduces “bad minima” but makes intuition hard
- Research shows many optima are connected, reducing real-world risk
Background
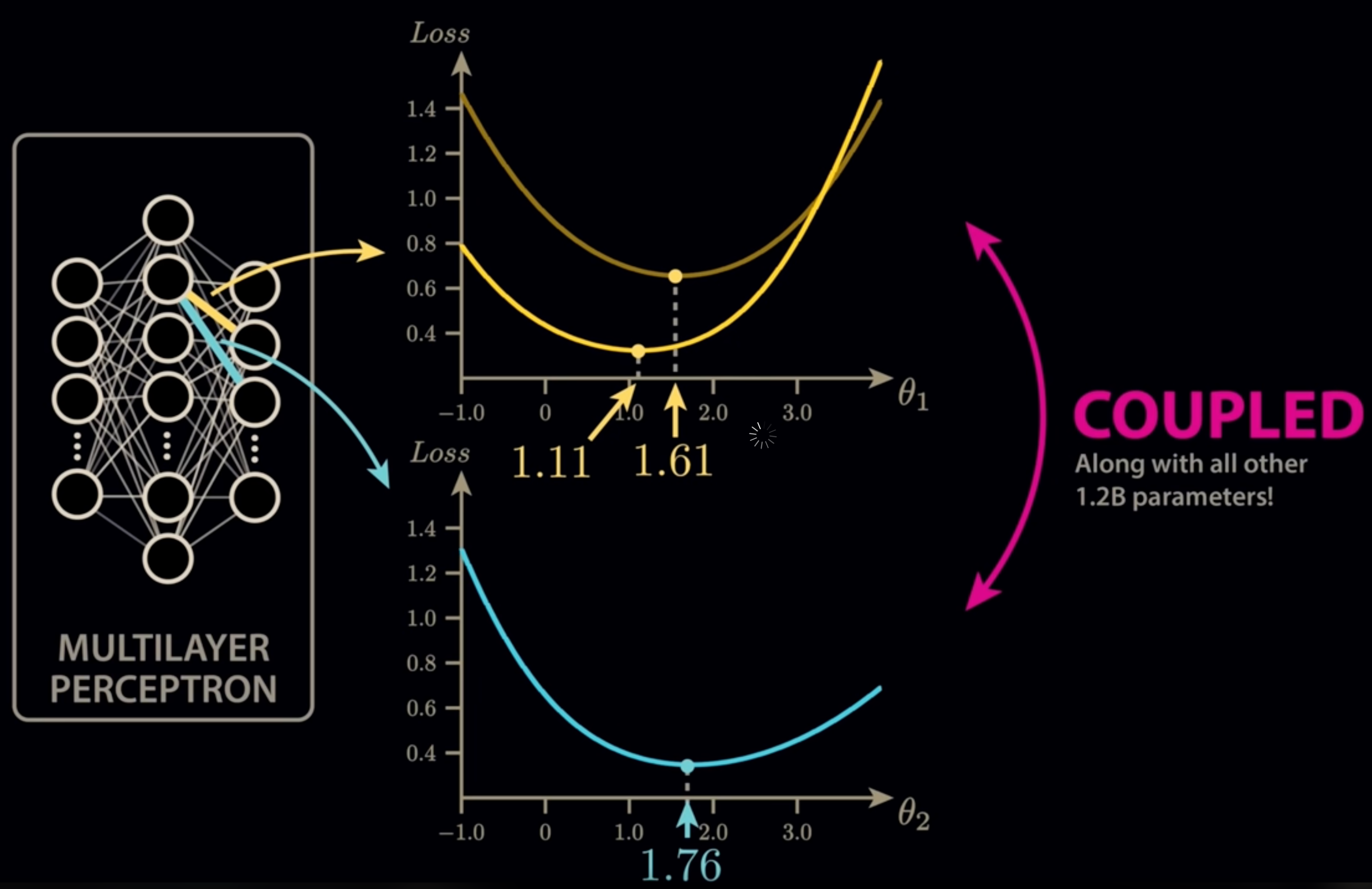
🤖 Gradient descent is the workhorse behind training large language models (LLMs).
💸 But with costs of millions per run, the risk of ending up in a suboptimal local optimum would be catastrophic.
📉 The loss landscapes of models with billions of parameters are unimaginably complex, making direct visualisation and intuition almost impossible.
What have I done:
I dove into the literature and shared insights about the interplay between dimensionality and optimisation:
- In very high-dimensional spaces, most local minima are not truly bad — they are saddles with escape routes.
- Mode connectivity research shows that what looks like separate optima are often connected by low-loss curves.
- This means training is less about getting “stuck” and more about finding paths through a giant valley of solutions.
IMHO:
🌄 While the math is reassuring, the risks remain when scaling models: data quality, weight initialisation, and hyperparameter choices can still make or break outcomes.
📈 Large parameter counts and huge datasets increase the odds of reaching a near-global optimum — but not automatically.
🥵 If this feels too abstract, I highly recommend Stephen Welch’s Welsh Labs visualisation of high-dimensional loss surfaces (link in comments).
❤️ Huge respect to the open AI community: papers, repos, blogs, and videos make it possible to reason about these hard problems together. At Comma Soft AG, we actively explore these challenges while developing domain-specific LLMs for Alan.de.
❤️ Feel free to reach out and like if you want to see more of such content.
#freeeducation #llm #artificialintelligence #machinelearning