How to find the Best Local Restaurant for you Right Now
We tackled the challenge of inadequate restaurant filter options by implementing two interconnected projects: Menu Card Extraction and Restaurant Business Analytics. Using a combination of machine learning models and human-in-the-loop QA, we processed semantic structured data from menu photos, overcoming issues like image quality and design variations, and ultimately creating a comprehensive XML structure for enhanced business analytics and accurate restaurant classifications.
I love living in big cities because they offer a great selection of varied international food. I've often found myself unsure about which restaurant to choose. There are websites that provide support, but they often lack the right filter options, such as specifying how much a main course should cost or identifying which diets, such as vegan, are accommodated without limiting choices to side dishes.
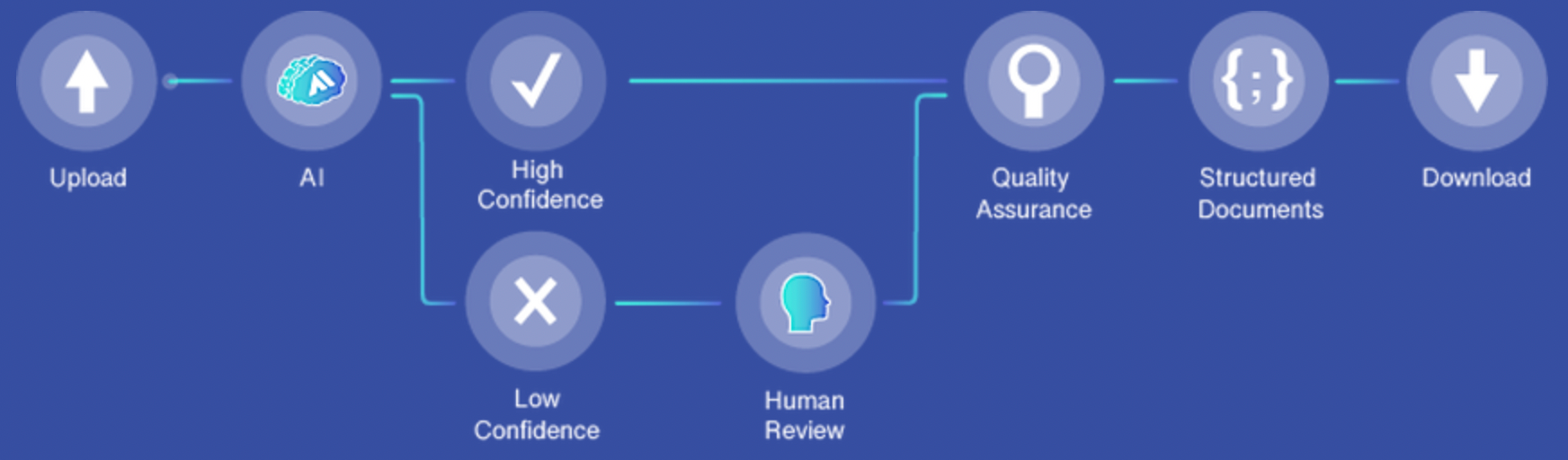
We presented our project at Fedger as part of a Startup Safari. We aimed to close this gap with two interconnected projects: Menu Card Extraction and Restaurant Business Analytics. In Menu Card Extraction, the challenge was to process the semantically structured data contained in photos of menus. This structured data included categories, dish names, quantities, ingredients, prices, and identification numbers. The raw data had many issues, including image quality problems such as distortion, blurring, and rotation. Additionally, the menus had errors like duplicate identification numbers, description mistakes, typos, unclear manual additions, and more. The design of the menus was sometimes challenging, especially with customizable options like "build your own burger." All of this information is crucial for determining price information or vegan options.
For the technical implementation, a combination of several machine learning models was necessary, supplemented by human-in-the-loop QA. Here is a simplified overview of the pipeline: Colleagues labeled the initial menus using an in-house annotation tool, creating boxes around relevant items and classifying the information they contained. Two significant computer vision approaches then replicated this recognition. First, a region proposal network identified these boxes, i.e., segments. In the second step, these segments were cut out and classified. There were different approaches to extract them hierarchically or in a single shot. The extracted regions were then processed with optical character recognition (OCR) to obtain the final text layer. A semantic XML structure was created from these elements.
In various iterations, human support corrected the labeled boxes, improving output quality and providing new training data. The data extracted and annotated in this way was then used for further business analytics, such as classification into price regions or cuisines offered. For example, tapas restaurants were often rated as cheap because the average price couldn't be compared with main dishes from other restaurants. By incorporating POS data, we improved these predictions. Numerous optimizations were necessary throughout these data aggregation and prediction steps. However, it was always enjoyable to work on an AI or computer vision project related to my passion for international food. Thanks to the great team, I was always able to learn a lot from and with them.