SANSA - ML and Analytics on Knowledge Graph Data distributed and scaled over CPU Clusters
Big Data RDF Processing and Analytics Stack built on Apache Spark and Apache Jena
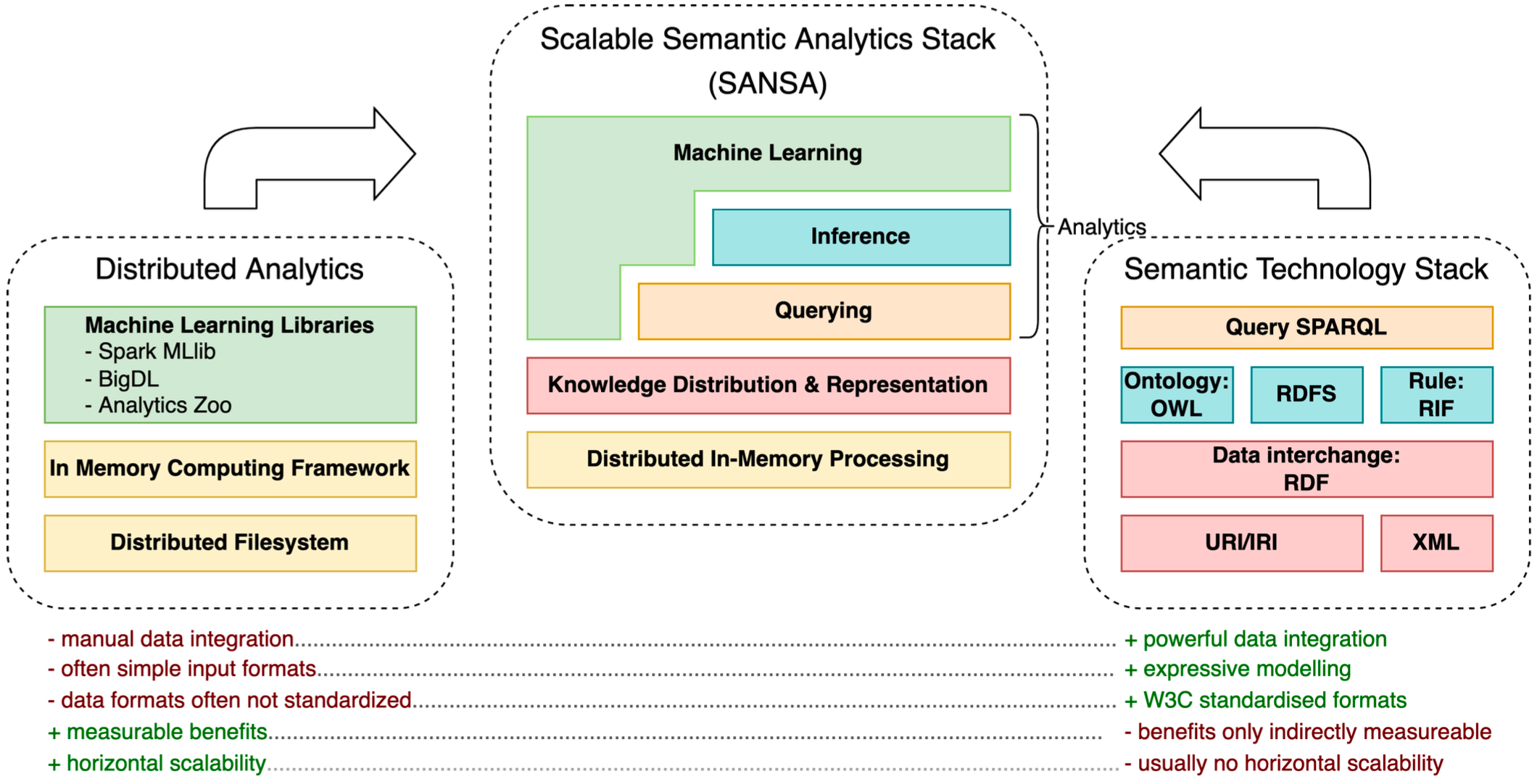
When KGs are the core of data analysis projects, it must be considered what immense sizes they can have. This data scale leads to the fact that KG no longer fits into the main memory~(RAM) of classic computers when it comes to processing and further use. The main memory in computers is limited by the modules produced and available on the market for a machine. Likewise, upgrading becomes disproportionately expensive from the point where the hardware specifications leave the space of classic consumer hardware. The solution is to scale horizontally as hardware requirements increase. This horizontal scaling means that several computers in a cluster provide the necessary resources. Software frameworks are used that enable the distributed management and processing of data. The Hadoop Distributed File System (HDFS) is used for the distributed management of data. Apache Spark is widely used for distributed data processing, particularly in data analysis pipelines. The existing Apache Spark data analysis pipelines require data in tabular form. The Scalable Semantic Analytics Stack SANSA was developed in this context. It provides methods to operate natively on RDF KGs by using Apache Spark and Apache Jena.
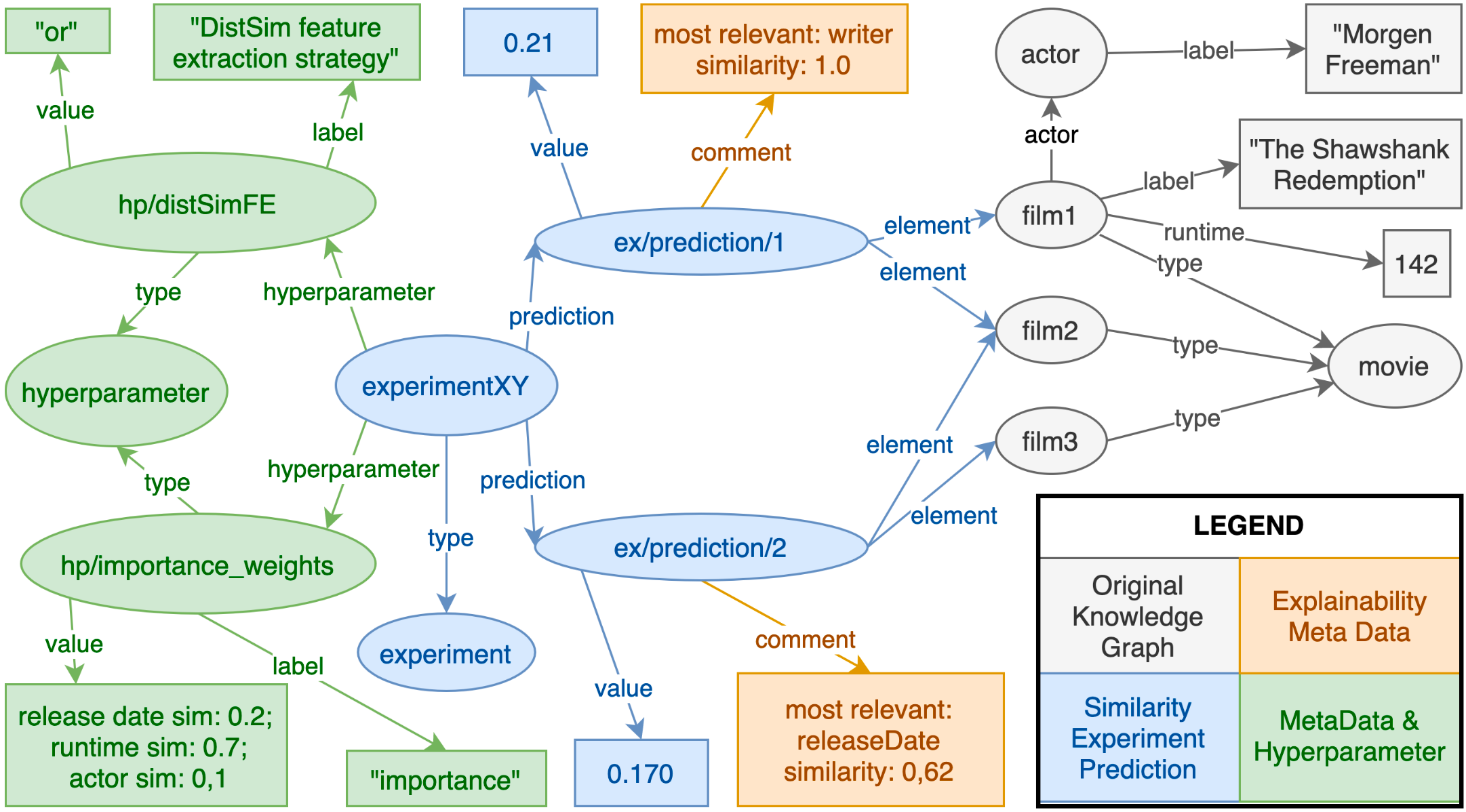
Distributed execution of ML pipelines and data analytics on KG data have unique challenges in feature retrieval. The graph traversal, the embeddings, and feature collection across multiple samples distributed over multiple machines are technical challenges. Cluster communication of multiple machines is a bottleneck because of the needed network connection between the machines. Within our work, we investigate the opportunities of scalable distributed semantic similarity estimations and downstream machine learning pipelines on multi-modal KG data.